
Sprache verstehen und anwenden, Muster erkennen oder Probleme lösen: Bereits als Kind wiederholen wir Abläufe solange, bis unser Erfahrungsschatz ausreicht, wir neue Fähigkeiten beherrschen oder uns neue Zusammenhänge erschließen. Bei der Anwendung von Machine Learning Verfahren bringen wir Maschinen eine ähnliche Art des Lernens bei. Datensatz für Datensatz lernen sie Prinzipien unserer Lebenswelt kennen, um unter anderem uns Menschen besser zu verstehen und auf uns reagieren zu können. So nutzen und verstehen sie mittlerweile unsere Sprachen, erkennen Probleme und bieten uns schnelle Lösungen an. Inzwischen sind intelligente Algorithmen in viele Bereiche unseres Lebens integriert. Die grundlegenden Mechanismen dahinter sind meistens jedoch nicht auf den ersten Blick ersichtlich. Für eine mündige Nutzung der Technologien ist dieses Wissen jedoch zwingend erforderlich.
Insbesondere Schüler*innen sollten die Konzepte nachvollziehen und verstehen, die das Zeitalter der Digitalisierung und somit ihre Gegenwart und Zukunft prägen. Die Vermittlung von Kenntnissen über Künstliche Intelligenz und Machine Learning rücken dadurch immer mehr in den Fokus der Didaktik. Mit der vorliegenden Handreichung erhalten Lehrkräfte einen kompakten Einstieg in diese Themenfelder. Neben Erklärungen zum Verständnis bietet das Material eine modulare Anleitung für den direkten Einsatz im Unterricht.
Ich wünsche viel Freude beim Lesen.
Thorsten Leimbach
![]()
Leiter der Roberta-Initiative am Fraunhofer-Institut
für Intelligente Analyse- und Informationssysteme IAIS
Bestimmt haben Sie sich schon mal die Frage gestellt, warum Ihnen bei Amazon oder bei Netflix bestimmte Produkte oder Serien empfohlen werden, die gut oder weniger gut zu Ihren tatsächlichen Vorlieben passen. Oder Sie haben in der Zeitung von selbstfahrenden Autos im Straßenverkehr gelesen, mit positiven oder negativen Schlagzeilen.
Auch wenn ein → Sprachassistent im Telefon Ihre gesprochenen Suchanfragen erkennt, werden im Hintergrund komplexe Programme ausgeführt, die den Sprachassistenten flexibel auf seine Umgebung reagieren lassen. Solche intelligenten Programme basieren auf → Machine Learning Verfahren und stellen eine wichtige Entwicklung im Zusammenhang mit der zunehmenden Anzahl und Bedeutung von Technologien aus dem Bereich der → Künstlichen Intelligenz dar.
Beide Begriffe werden im Alltag häufig synonym verwendet, doch was ist Machine Learning (ML) und worin besteht der Unterschied zu Künstlicher Intelligenz (KI)? Wie funktioniert es und welche Rolle spielt Machine Learning bereits heute in unserem Alltag? Welche Auswirkungen ergeben sich für unsere Gesellschaft und welche Entwicklungen sind in der Zukunft zu erwarten? Welche ethischen und gesellschaftlichen Aspekte müssen dabei besonders beachtet werden, um ein gutes Zusammenleben von Menschen und Maschinen zu ermöglichen? Wie können wir Schüler*innen in diesen Diskurs zu Machine Learning einbinden, sodass sie lernen, aktiv an der zivilgesellschaftlichen Auseinandersetzung zu partizipieren?
Die vorliegende Publikation bietet Anregungen und konkrete Beispiele für den Einsatz im Unterricht. Anhand von Unterrichtsverlaufsplänen und begleitender Arbeitsblätter und Materialien ist eine praxisnahe Handreichung für die Schule entstanden. Die Beschäftigung mit dem Thema Machine Learning hilft, ein Verständnis dazu aufzubauen und mehr Transparenz zu schaffen. Dabei soll der Blick zum einen dafür geöffnet werden, welche Möglichkeiten ML-Anwendungen bereits heute bieten; zum anderen soll ebenso für die Risiken und Herausforderungen sensibilisiert werden, die sich daraus ergeben. In der Auseinandersetzung mit Anwendungsszenarien und konkreten Beispielen aus dem Alltag lernen die Schüler*innen Argumente für eine Begründung des eigenen Standpunktes zu formulieren und festigen ihre kritische Analysefähigkeit.
Das Material bietet Informationen, vielfältige Methoden und Praxisanregungen für diesen notwendigen Diskurs im Unterricht, um das Thema Machine Learning ohne Vorkenntnisse mit Schüler*innen zu behandeln. Die Jugendlichen erlangen ein grundlegendes Verständnis, sodass sie dazu befähigt werden, eine eigene Haltung zu dem Thema aufzubauen und sich in zivilgesellschaftlichen Fragen des demokratischen Zusammenlebens partizipativ einbringen zu können.
Sei es beim Lesen von Sportnachrichten, bei der Auswahl von Musiktiteln oder auch beim Empfang von Paketen: Auch, wenn es uns nicht immer an jeder Stelle bewusst ist, so werden schon viele Bereiche unseres Alltags durch auf Machine Learning basierende Prozesse und Programme gesteuert – und diese Entwicklung soll in den kommenden Jahren noch rasant an Wachstum gewinnen.¹
Die Technologie durchdringt alle menschlichen Lebensbereiche, deshalb muss die Frage diskutiert werden, wie wir mit intelligenten Maschinen in Zukunft zusammenleben wollen. Der Begriff Maschine meint in diesem Zusammenhang nicht (nur) physische Stahlbauten, die z.B. mittels Motoren bewegt werden können. Er ist hier als übergeordneter Begriff zu verstehen, der sowohl physische Computer und → Roboter als auch digitale Programme und Apps umfasst. Es geht nicht länger um ein bloßes Bedienen der Maschinen, um ein Nebeneinander, denn der Grad an Interaktion steigt. Roboter assistieren bei Operationen, helfen bei der landwirtschaftlichen Arbeit und unterstützen bei der Auslieferung von Paketen. Die Interaktionen zwischen Mensch und Maschine verweben und verzahnen sich in solch einem Maß, dass es vielmehr um ein Miteinander geht, ein gemeinsames Zusammenarbeiten, wenn Aufgaben und Verantwortung an Maschinen abgegeben werden. Die mit der Mensch-Maschine-Interaktion ausgelösten ethischen Fragestellungen sind nur ein Teilaspekt der ethischen Gesichtspunkte des Machine Learnings.
Wie viel Verantwortung kann der Mensch an die Maschine abgeben? Und wie viel Informationen benötigt diese, um ihre Aufgaben gut zu erfüllen? Welche Aufgaben sollte der Mensch niemals den Maschinen überlassen? Die aufgeworfenen Fragen bergen Herausforderungen, für die es Antworten zu finden gilt, um Richtlinien für ein gutes Miteinander zu entwickeln, Missbrauch und Gefahren für den Einzelnen und die Gesellschaft zu unterbinden, damit alle gleichermaßen an den Vorteilen der technischen Errungenschaft partizipieren können.
Um die Vorteile von Machine Learning einer breiten Öffentlichkeit zugänglich zu machen, ist es wichtig, dass deren Ausgestaltung und Regulierung nicht durch die Interessen Einzelner geleitet werden. Dabei liegt die Aufgabe zur Definition von Richtlinien nicht allein bei der Politik: Vielmehr ist es eine gesamtgesellschaftliche Verantwortung, die digitalisierte Welt mitzugestalten. Jede*r ist aufgefordert, für persönliche und gesellschaftliche Freiheit Verantwortung zu übernehmen und zu partizipieren.
Ein grundlegendes Verständnis für die Funktionsweise und die ethischen wie gesellschaftlichen Auswirkungen von ML sind notwendig: Es geht um eine Transferleistung zur Mitgestaltung der Gesellschaft und damit um die Sicherung der Demokratie. Die positive Entwicklung braucht viele Ideen und Perspektiven, weshalb jede*r aufgefordert ist, mitzudenken.
ML-basierte Maschinen werden zukünftig in vielen Bereichen zunehmend Entscheidungen selbstständig treffen können. Damit gehen neue ethische und rechtliche Fragen einher.
Die zentrale ethische Herausforderung ist es, die Maschinen und Programme so zu gestalten, dass sie mit unseren Gesellschafts-, Rechts- und Wertvorstellungen kompatibel sind. Diese gesellschaftliche Debatte muss jetzt beginnen und auch mit der heranwachsenden Generation geführt werden.
Es gilt dabei, Antworten auf viele ethische Fragestellungen zu finden, wie z.B.:
→ Dürfen → Algorithmen über Menschenleben entscheiden?
→ Wer ist bei Unfällen eines selbstfahrenden Autos verantwortlich?
→ Welche Rechte haben Roboter?
→ Müssen Unternehmen für Roboter Steuern zahlen, wenn durch sie Arbeitsplätze wegfallen?
→ Über welche Daten müssen die Programme und Anwendungen verfügen, um ihre Aufgabe zu erfüllen?
→ Wenn menschliche Entscheidungen mathematisch vorhersehbar sind, kann der Mensch dann überhaupt noch eigenständige Entscheidungen treffen?
→ Ist es noch Kunst, wenn ein Musikstück von einem Algorithmus komponiert wird?
Machine Learning Verfahren können zudem zu falschen Ergebnissen gelangen, wenn sie z.B. auf einer schlechten Datengrundlage beruhen oder falsche Berechnungen durchführen. Dadurch können diskriminierende Entscheidungen getroffen werden, die negative Auswirkungen auf die betroffenen Menschen haben. Es ist wichtig, zu verstehen, dass nicht nur menschliche, sondern auch rechnerische Entscheidungen keine hundertprozentige Sicherheit bieten können.
Jugendliche, die im 21. Jahrhundert aufwachsen, sind umgeben von vielen Technologien, die sie permanent und überallhin begleiten. Nahezu alle Jugendlichen zwischen 12 und 19 Jahren besitzen ein eigenes Smartphone, Dreiviertel haben einen eigenen Computer.2 → Wearables (z.B. Fitnesstracker) und digitale → Sprachassistenten (z.B. Siri) haben eine wachsende Bedeutung für Kinder und Jugendliche. All diese Geräte nutzen verschiedenartige Daten, um ihre Anwender*innen bei unterschiedlichen Aufgaben zu unterstützen.
Video- und Musikstreamingdienste (→ Streaming) gehören zum Alltag und werden von ca. Dreiviertel der Jugendlichen genutzt. Diese Werte steigen mit zunehmendem Alter der Jugendlichen, liegen jedoch auch bei den 12- bis 13-Jährigen nur geringfügig unter dem Durchschnitt der gesamten Altersspanne.3 Unter Jugendlichen sind YouTube und Spotify die beliebtesten Online-Dienste für Video- und Musikstreaming.4
Die meisten Streamingdienste beinhalten dabei sog. Empfehlungsdienste, die eine Form von Machine Learning Anwendungen sind. Dabei macht das System seinen Nutzer*innen Vorschläge und Empfehlungen z.B. zu Videos, die ihnen „auch gefallen könnten“. Diese Empfehlungen beruhen auf Daten, die das System über sie/ihn selbst und andere Nutzende, die ähnliche Videos gesehen haben, gesammelt hat. Basierend auf vielen Nutzerdaten lernten die Programme, welche Inhalte sie welchen Nutzer*innen vorschlagen sollen.
Auch große Online-Versandhändler, die für Jugendliche altersbedingt noch eine geringfügige Rolle spielen, verwenden Empfehlungsdienste. Ihr Ziel ist es, das Klick- und Kaufverhalten der Nutzer*innen durch Hinweise wie „andere Kunden kauften auch“ zu beeinflussen. Menschen müssen lernen, ihr Verhalten nicht einzig und allein an Empfehlungen und Vorschlägen einer unsichtbaren Maschine auszurichten. Sie müssen die Systematik dahinter verstehen, um selbstbestimmt Entscheidungen – dafür oder dagegen – treffen zu können. Besonders Jugendliche sind entwicklungsbedingt in ihren Entscheidungen oftmals noch stark durch äußere Faktoren beeinflussbar und müssen bei der Aneignung der notwendigen Kompetenzen im pädagogischen Kontext unterstützt werden.
Die Welt von heute ist geprägt von technologischen Entwicklungen in vielen verschiedenen Bereichen unseres Alltags. Dabei finden zunehmend Technologien mit → Künstlicher Intelligenz (KI) Einzug in unser Leben. KI ist ein Sammelbegriff für verschiedene Verfahren und Programme. Die beiden Begriffe „künstlich“ und „Intelligenz“ weisen darauf hin, dass die Verfahren von Menschen künstlich erschaffen wurden, aber auch das intelligente Verhalten von Menschen nachahmen sollen.
Programmanwendungen mit Künstlicher Intelligenz versuchen durch unter- schiedlich programmierte Methoden, die kognitive Arbeitsweise eines Menschen zu imitieren, um Aufgaben zu bewältigen, die mit Computern als reinen Rechenmaschinen vor vielen Jahrzehnten noch nicht denkbar waren. Während in Hollywood schon seit langem Filme mit selbst denkenden oder fühlenden Robotern produziert werden, ist die Realität noch weit entfernt von menschenähnlichen Robotern à la Pinocchio („A. I. – Künstliche Intelligenz“) oder Robotern, die uns rund um die Uhr bedienen („I, Robot“). Solche unabhängig denkenden Maschinen werden als → starke Künstliche Intelligenz bezeichnet. Im Gegensatz dazu finden sich in unserem Alltag bereits viele Anwendungen, die über sog. → schwache Künstliche Intelligenz verfügen, weil sie durch reaktives Verhalten in ihrem jeweiligen Aufgabenbereich intelligentes Verhalten nachahmen. Zu den Programmen mit schwacher Intelligenz gehören z.B. die → Spracherkennung, → Gesichtserkennung und inhaltliche → Bildanalyse.
Die Basis von vielen dieser Anwendungen bildet das → Machine Learning (ML), das Maschinelle Lernen. Das vorliegende Unterrichtsmaterial nutzt vor- wiegend den englischen Begriff, da er sich im fachlichen Sprachgebrauch und in der öffentlichen Berichterstattung zu diesem Thema etabliert hat. Machine Learning Verfahren ermöglichen es, dass Programme intelligent auf ihre Umwelt reagieren können. Sie zielen darauf, dass Programme ohne explizite Programmierung eines konkreten Lösungswegs → automatisiert sinnvolle Ergebnisse liefern. Das Programm „lernt“ anhand von Beispielen und verbessert mit zunehmender Erfahrung seine Ergebnisberechnungen.
Um zu verstehen, was ML-Anwendungen von anderen unterscheidet, ist es wichtig zu wissen, wie Programme im klassischen Sinn funktionieren. Eines der wichtigsten Prinzipien von Computerprogrammen liegt darin, dass es auf die Eingaben und Interaktionen von Nutzer*innen in fest vorgegebener Art und Weise reagiert.
Am Beispiel eines Textverarbeitungsprogrammes bedeutet dies z.B.:
→ Wenn der/die Nutzer*in die Speichern-Funktion anklickt, dann wird das Dokument auf dem Computer gespeichert.
→ Wenn der/die Nutzer*in ein Wort markiert und anschließend die Kursiv-Funktion anklickt, dann wird das Wort kursiv gestellt.
Es handelt sich also häufig um Wenn-Dann-Beziehungen. Dabei muss für das Programm anhand des zugrunde liegenden Programmcodes (→ Code) eindeutig klar sein, auf welche Eingabe es wie reagieren soll.
Im Folgenden erläutern wir das Beispiel eines Programms, das mithilfe von Kameratechnik im Vorbeifahren Verkehrszeichen erkennen soll, um den Fahrenden bei der Einhaltung des aktuellen Tempolimits zu unterstützen.5 Das Programm kann auf dem Smartphone installiert sein und während der Fahrt mit der Kamera nach vorne gerichtet werden. Wenn dieses Programm nach dem klassischen Prinzip funktionieren würde, dann könnte folgende Wenn-Dann-Beziehung gelten:
→ Wenn die Eingabe im Programm ein 50 km/h Zeichen darstellt, dann zeige dem Fahrer das 50 km/h Zeichen dauerhaft auf dem Smartphone an.

Das erscheint auf den ersten Blick einfach und nachvollziehbar. Das Programm kann das Eingabebild pixelweise (→ Pixel) untersuchen und überprüfen, ob es seiner Vorlage eines 50 km/h Zeichens entspricht. Gleichzeitig stellt sich die Frage, in welcher Form das Programm zur Verkehrsschildererkennung eigentlich die Daten erhält, um festzustellen, ob es sich dabei um das 50 km/h Zeichen handelt? Der/die Fahrer*in wird sicherlich nicht die oben verwendete Bilddatei in das Programm hochladen. Vielmehr muss das Programm selbst „auf einen Blick erkennen“, dass sich im Blickfeld der Kamera ein 50 km/h Zeichen befindet. Es muss das Zeichen in seiner natürlichen Umgebung erkennen – und nicht nur vor weißem Hintergrund mit frontalem Draufblick und unverdeckt von Blättern oder Schnee.
Doch woher weiß das Programm, welche Pixel zum Zeichen gehören und welche zum Hintergrund? Woher weiß es, wie das Schild aussehen würde, wenn es schief wäre? Auch die folgenden Situationen müssen vom Programm erkannt werden können:

Für uns Menschen ist das eine vergleichsweise einfache Aufgabe, die wir mithilfe unserer kognitiven Fähigkeiten für die Verarbeitung visueller Reize lösen können. Uns reicht oftmals ein kurzer Blick auf ein Zeichen und wir wissen auch für die Zukunft, wie es z.B. aus anderen Blickwinkeln und mit anderen Zahlen aussieht und wir lernen schnell, wie das Verkehrszeichen in anderen Ländern dargestellt wird. Für den Computer ist dies jedoch nicht so einfach und es ist unmöglich, im Programm Fotos für alle möglichen Fälle (diverse Blickwinkel, Hintergründe, Lichtverhältnisse, Größen etc.) abzuspeichern, damit er diese in Sekundenschnelle mit dem aktuellen Kamerabild vergleicht, um die perfekte Übereinstimmung zu finden. Es wäre nicht nur unmöglich, Fotos für Milliarden oder mehr mögliche Fälle herzustellen oder abzuspeichern, es würde auch viel zu lange dauern, um jedes bereits bekannte Foto pixelweise mit dem Kamerabild zu vergleichen.
Das Programm muss stattdessen erst lernen, die vorhandenen Daten sinnvoll zu analysieren und auf deren Basis die richtigen Schlussfolgerungen zu ziehen. Dafür muss es mit verschiedenen Daten trainiert werden, z.B.:

Vereinfacht: Es könnte darauf trainiert werden, die Zahlen innerhalb eines roten Kreises zu erkennen – und zwar aus unterschiedlichen Blickwinkeln, unter verschiedenen Lichtbedingungen, mit teilweisen Verdeckungen usw. Je nachdem, was das Programm außerdem leisten soll, müsste es entsprechend trainiert werden, z.B.: Zahlen auf anderen Formen erkennen (um international einsetzbar zu sein), weitere Verkehrsschilder erkennen (Verbot der Einfahrt, Stop oder Fahrtrichtungspfeile).
Die Bilder, die dem Programm zum Lernen präsentiert werden, heißen → Trainingsdaten. Mithilfe eines komplexen → Algorithmus im Hintergrund lernt das Programm, diese Trainingsfotos einem sog. → Label (dt. Bezeichnung, hier: Kategorietitel) zuzuordnen. Mit diesem zugeordneten Label kann anschließend erneut eine Wenn-Dann-Beziehung hergestellt werden.
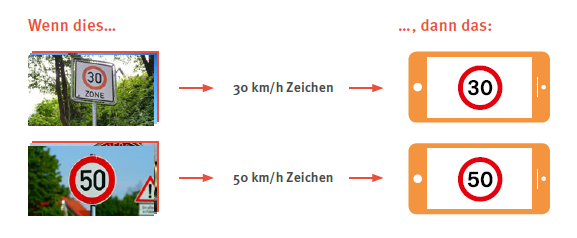
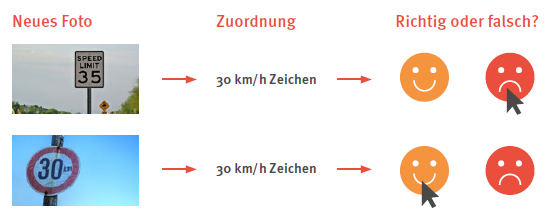
Beim Trainieren erstellt das Programm aus den → Mustern, die es auf den Fotos erkennt, ein eigenes → Modell. Dieses Modell stellt eine Verallgemeinerung der Trainingsdaten dar, das anhand von verschieden gewichteten Merkmalen in den Fotos erstellt wurde. Mithilfe dieses Modells ergeben sich für zukünftige, noch unbekannte Fotos berechnete Wahrscheinlichkeiten, nach denen ein neues Foto einem bestimmten Label zugeordnet wird. Der zugrunde liegende Algorithmus gibt nur vor, wie das Programm dieses Modell erstellen kann, um zukünftige Daten richtig einordnen zu können, ohne ihm jedoch exakte Eingaben und Reaktionen vorzugeben. Dieses Training kann mithilfe von sog. künstlichen → Neuronalen Netzen erfolgen. Dabei ist z.B. jedes Neuron für einen kleinen Bildbereich zuständig und erkennt die Muster darin. Die Berechnungen aller Neuronen fließen zum Schluss in einem Modell zusammen. Das fertige Programm wird später dieses Modell benutzen und sich bei jedem Kamerabild für dasjenige Label entscheiden, wofür es die höchste Wahrscheinlichkeit, also den größten Grad an Musterübereinstimmung, berechnet hat. Man spricht auch von einer Klassifikation der Daten. Das Programm trifft eine sichere (oder unsichere) Vorhersage für das, was es erkennt. Die Richtigkeit dieser Vorhersagen hängt oft und stark von der Qualität der Trainingsdaten ab.
Mit sog. → Testdaten kann ein erstelltes Modell auf seine Richtigkeit überprüft werden. Die Überprüfung kann z.B. im Rahmen der Programmentwicklung von menschlichen Kontrolleur*innen durchgeführt werden, die entscheiden, ob die Einordnung eines Fotos zu einem bestimmten Label richtig oder falsch war. Wenn sie falsch war, dann ist es die Aufgabe der Programmierer*innen, die mögliche Fehlerquelle herauszufinden und den Lernalgorithmus zu verbessern bzw. die ausgewählten Trainingsdaten zu verändern oder neue hinzuzufügen, sodass immer weniger Testdaten falsch klassifiziert werden.
Die Gesichtserkennung beim Smartphone funktioniert auf ähnliche Art und Weise. Mit ihrer Hilfe soll sich der/die Nutzer*in allein mit einem Blick in die Kamera identifizieren und dadurch das Gerät entsperren können. Das Programm im Hintergrund hat durch entsprechende Trainingsdaten von verschiedenen Gesichtern ein Modell erstellt. Das Gesicht des/der Nutzenden wird als Referenz für das Label „Benutzer*in dieses Smartphones“ verwendet und jedes später getestete Gesicht wird entweder als „Benutzer*in dieses Smartphones“ oder „Nicht Benutzer*in dieses Smartphones“ klassifiziert. Hier stellt sich – ohne Einbeziehung weiterer Sicherheitsmerkmale – eine spezifische Schwierigkeit dieser Technik dar: Kann mein Smartphone auch mit einem lebensgroßen Foto meines Gesichts entsperrt werden?
Es gibt verschiedene → Lernstile im Machine Learning, die je nach Zielsetzung der Anwendung und zur Verfügung stehender Ressourcen eingesetzt werden können. Das hier vorgestellte Verfahren stellt in Grundzügen nur eine mögliche Form des maschinellen Lernens dar, die als → überwachtes Lernen bezeichnet wird. Dabei werden dem Computer von den programmierenden Menschen die möglichen Label für die Daten vorgegeben und das Programm soll zukünftige Daten zu diesen Labels zuordnen. Das Gegenteil davon wäre das sog. → unüberwachte Lernen. Hierbei erhält das Programm lediglich eine Menge von Daten, bei denen es ohne Vorgaben nach ähnlichen Mustern suchen soll und z.B. ähnliche Fotos als einer Gruppe zugehörig markieren soll. Ein Beispiel für unüberwachtes Lernen ist die Analyse großer Gendatensätze und die Sortierung der Genome in Gruppen mit ähnlichen Merkmalen. Die detaillierte Betrachtung vieler verschiedener Machine Learning Verfahren ist jedoch nicht Gegenstand dieses Unterrichtsmaterials.
1 Vgl. Fraunhofer-Allianz Big Data (Hrsg.) (2017): Zukunftsmarkt Künstliche Intelligenz. Potenziale und Anwendungen, S. 22ff
www.iuk.fraunhofer. de/content/dam/iuk/de/ documents/KI-Studie_Ansicht_201712.pdf
2 Medienpädagogischer Forschungsverbund Südwest (MPFS) (Hrsg.) (2018): JIM-Studie 2018. Jugend, Information, Medien. Basisstudie zum Medienumgang 12- bis
19-Jähriger in Deutschland. www.mpfs.de/fileadmin/ files/Studien/JIM/2018/Studie/JIM_2018_Gesamt.pdf
3 Ebd.
4 Ebd.
5 Beispiel für ein Fahrassistenzsystem: www.connect.de/testbericht/ mydriveassist-test-fahrassistenz-app-android-ios-3185291.html